Collections bundle related documents into a single searchable unit. Connect a collection to an index node and any file in it — PDFs, Markdown notes, HTML, transcripts — becomes queryable from your workflows.
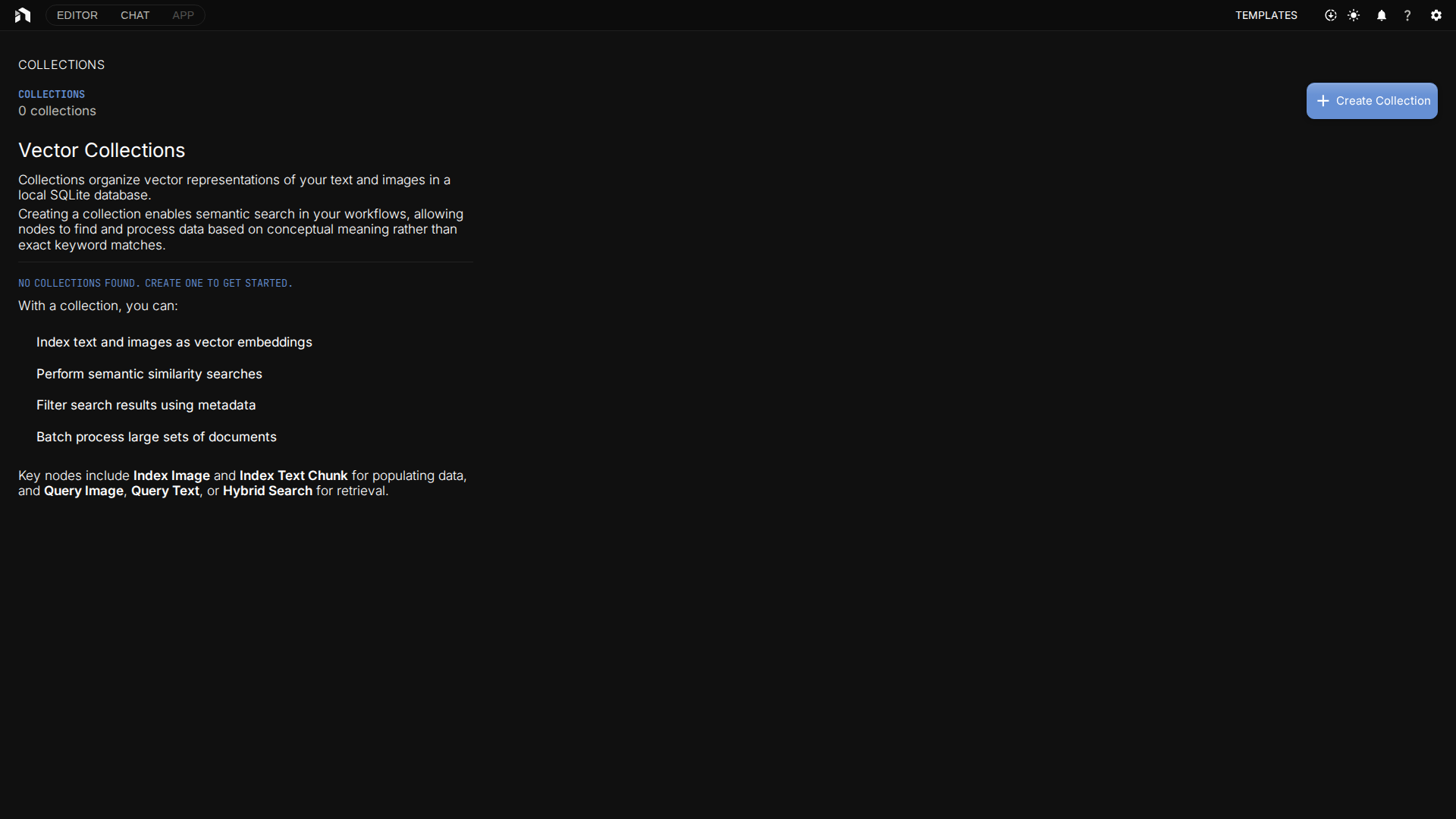
Opening Collections
Navigate to Collections from the left sidebar, or go directly to /collections. The explorer shows every collection you’ve created with counts of documents and the last time they were indexed.
Creating a Collection
- Click New Collection in the top-right.
- Give it a name and an optional description.
- (Optional) Associate a default embedding model.
- Drag documents into the collection — or import a folder from the Asset Explorer.

Collections accept any file type, but only text-extractable formats are indexed:
| Format | Extracted |
|---|---|
| Text + layout (per page) | |
| DOCX / DOC | Body text |
| Markdown / TXT | Raw text |
| HTML | Stripped body text |
| CSV / TSV | Rows as records |
| EPUB | Chapter text |
Unsupported formats are stored but not indexed — still handy for reference inside a collection.
Managing Documents
Click a collection tile to open its details. You can:
- Add documents by drag-and-drop or the Upload button.
- Remove documents from the collection (doesn’t delete the underlying asset).
- Re-index after adding new documents or changing the embedding model.
- Preview any document inline with the built-in viewer.
Using Collections in Workflows
Collections shine in RAG pipelines:
- Add an IndexDocuments or HybridSearch node to your workflow.
- Connect the collection to its
collectioninput — the node menu will suggest the selector. - Run the workflow. The first run indexes the collection (embeddings + keyword index); subsequent runs reuse the index.
See the full pattern in the Cookbook → RAG.
Indexing Options
By default a collection uses the embedding model set in Settings → Default Models. Override per-collection from its settings:
- Embedding model — any embedding model from HuggingFace, OpenAI, Gemini, Cohere.
- Chunk size — tokens per passage (default: 512).
- Overlap — tokens shared between chunks (default: 64).
- Hybrid — enable BM25 alongside vector search for better recall on proper nouns.
See Indexing for deeper tuning notes.
Storage
Index data is stored alongside your workflow database in SQLite (via sqlite-vec). Nothing leaves your machine unless you’ve opted into a cloud provider for the embedding model.
For multi-user deployments, Supabase-backed collections are an option — see Supabase Deployment.
Related Docs
- Indexing — advanced chunking, hybrid search, maintenance
- Asset Management — add documents to the underlying asset library
- Cookbook → RAG — wire a collection into a workflow
- Chat with Docs example — end-to-end RAG workflow